On Scaffolding and Thinking in Agent Systems
The thinking transfers. The code doesn't.
In 2023 I built a RAG pipeline with four chunking strategies, a million vectors across Pinecone, and a system for dynamically assembling prompts from retrieved context. It took months. It worked. A year later, context windows grew large enough that half of what I built could be replaced by stuffing the document into the prompt.
The code became partially obsolete. But I came out of it with a deep understanding of vector embeddings, semantic retrieval, and subjective analysis — using LLMs to generate scores that create new dimensions for recall beyond what cosine similarity alone can do. That understanding carried directly into Klyde, into Eureka's entity system, into how I think about context in everything I build.
It Happened Again
Earlier this year I started building an agent orchestration system called ChiefOfStaff. I wanted agents that could execute toward goals across multiple projects over a long horizon — not a single conversation, but sustained operation with real consequences.
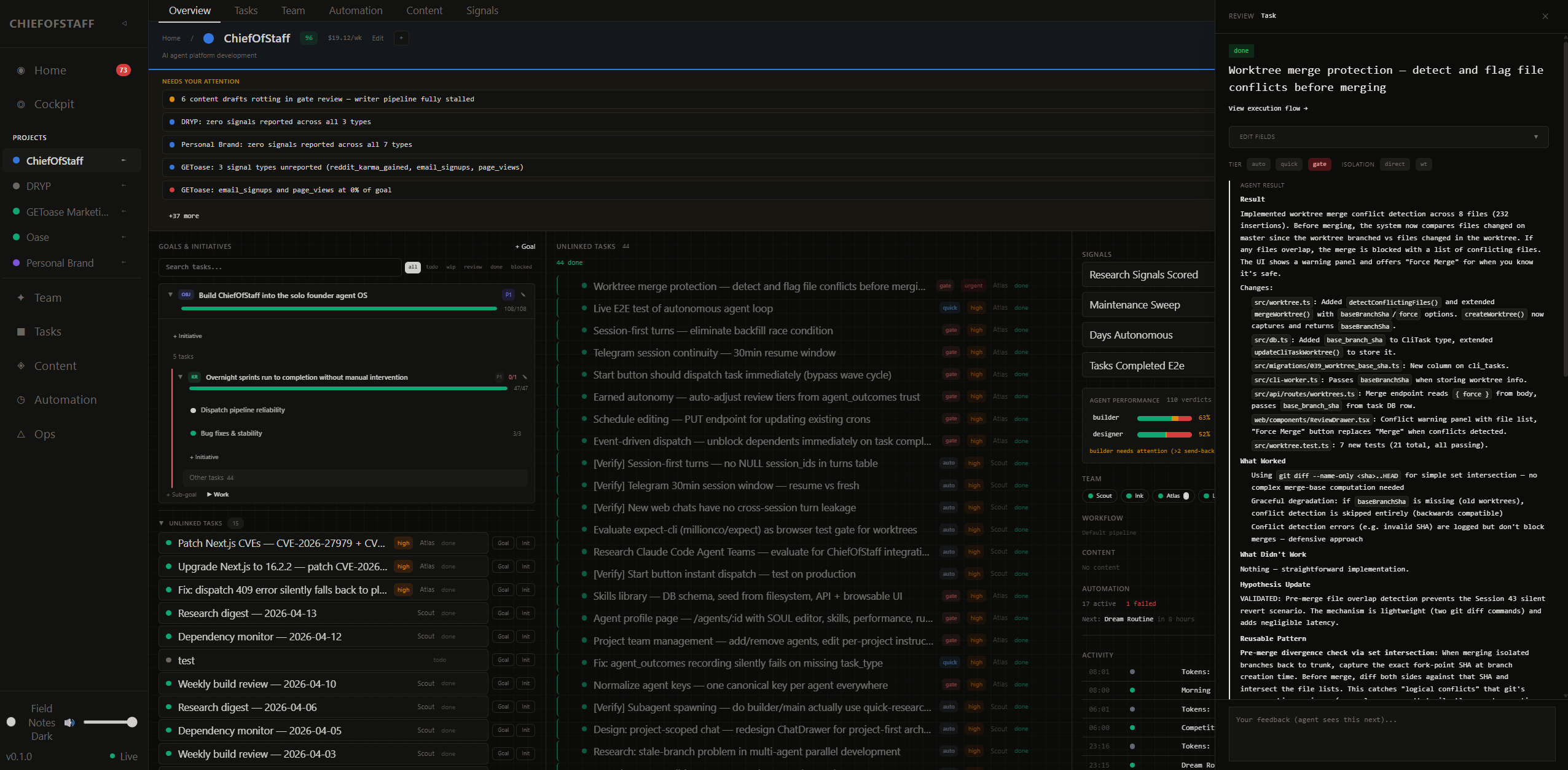
The system has scaffolding. Personality docs for each agent. Detailed skill procedures. A wave resolver dispatching tasks. Multi-step pipelines where one agent implements and a separate agent adversarially reviews. A review queue where every human decision generates structured data. Goal hierarchies — Objective, Key Result, Initiative, Task — so agents always know why they're doing something. The dispatch layer doesn't distinguish between scheduled work and judgment work — a cron wakes an agent the same way a manual task does.
Five agents run daily. Hundreds of review cycles processed. Code shipped, content published, research delivered. I use it every morning.
What Running It Taught Me
The system works like this: I define goals for my projects — what I'm trying to achieve, how I'll measure it, what initiatives support it. Agents pick up tasks with that full goal chain as context.
Objective "Build recognition in the AI engineering space"
Key Result "Publish 5 technical articles by Q2"
Initiative "Personal brand content sprint"
Task "Write: what I learned building RAG" → Ink (writer)
Task "Research: agent harness landscape" → Scout (researcher)
A researcher investigates a topic knowing it feeds a content campaign targeting a specific audience. A writer drafts knowing the strategic objective, not just "write a blog post." A builder ships code knowing which key result it moves.
When agents finish, work surfaces in a review queue. I approve, send back with notes, or discard.
Agents as perspective, not personality
There's a lot of conversation right now about agent personalities and soul docs. In ChiefOfStaff, agent memory is secondary to task and project context — the goal chain, the prior outcomes, the skill docs. But agents still matter as containers for perspective and skills. A researcher surfaces different things than a writer looking at the same input. A CMO frames a task differently than a builder. When the same project flows through different perspectives in sequence, the output is better than one generalist making multiple passes.
Agents are a major lever for controlling focus and output quality — just not through personality alone.
Multi-step pipelines
Different agents catch different things. The agent that built something has deep context and catches edge cases the spec didn't cover. A separate adversarial agent catches a different class of problems precisely because it didn't write the code — it brings a fresh perspective. Research supports this: agents can't reliably evaluate their own quality in isolation. So work flows through configurable pipelines where both get a pass:
code task: implement → self-review → adversarial-review → cleanup
content task: research → draft → self-critique → revise
Structured outcomes
The review data compounds faster than anything else in the system. Every decision — approve, send back, discard — generates structured data: which agent, what task type, what the verdict was, how long it took. Agents reference prior outcomes before starting similar work. The system calibrates — agents that produce consistently good work earn less oversight, code changes always require human review.
The idea is that those learnings accumulate. Month three output is meaningfully better than month one. Not because the model improved. Because the structured context improved. Whether that actually compounds over time is what I'm watching.
The Shifting Ground
There's a trend right now where people aren't sharing code. They're sharing the thinking — the decisions, the architecture, the reasoning — and giving agents the prompt to build the code. The code is becoming the easy part. The understanding of what to build and why is the hard part.
The models keep getting smarter. What required elaborate prompt engineering six months ago works with a straightforward instruction now. The rigid pipeline I built for adversarial review — the next model might be reliable enough to change how that works entirely. I built elaborate RAG infrastructure that better context windows made partially redundant. Some version of that will happen with agent orchestration too. This is the pattern.
Building Anyway
Every layer of AI tooling I've built has been scaffolding around the limitations of the current model. When models couldn't hold context, I chunked and retrieved. When agents couldn't self-direct, I built goal hierarchies and skill docs. When they couldn't self-evaluate, I built adversarial review pipelines. Each time, some of that scaffolding becomes unnecessary. Each time, the understanding of why it was necessary is what I carry forward.
You can't learn the thinking without building the scaffolding. I didn't understand retrieval until I built four chunking strategies and tested them at scale. I didn't understand agent orchestration until I ran five agents for months and watched where they fail.
The accumulated project context, the review history, the goal structures, the skill libraries — that data compounds in a way code doesn't. When a better model arrives, it flows through all of that accumulated context and the output changes immediately. The orchestration code might get rewritten. The learnings won't.
I don't know which parts of ChiefOfStaff survive the next model. I've been here before. The RAG practitioners from 2023 built the agent systems of today. The agent practitioners of today will build whatever comes next.