What I Learned Building RAG
In early 2023, my dev partner Sam and I were building a collaborative LLM chat platform called Unacog. We wanted users to be able to chat with their own documents — research papers, notes, PDFs, whatever they had. The concept of "retrieval augmented generation" existed in academic papers, but it wasn't in the zeitgeist yet. There were no RAG-in-a-box products. We were just trying to solve a problem: how do you give an LLM access to information it wasn't trained on?
We figured it out from first principles. Some of what we learned is still useful.
Chunking
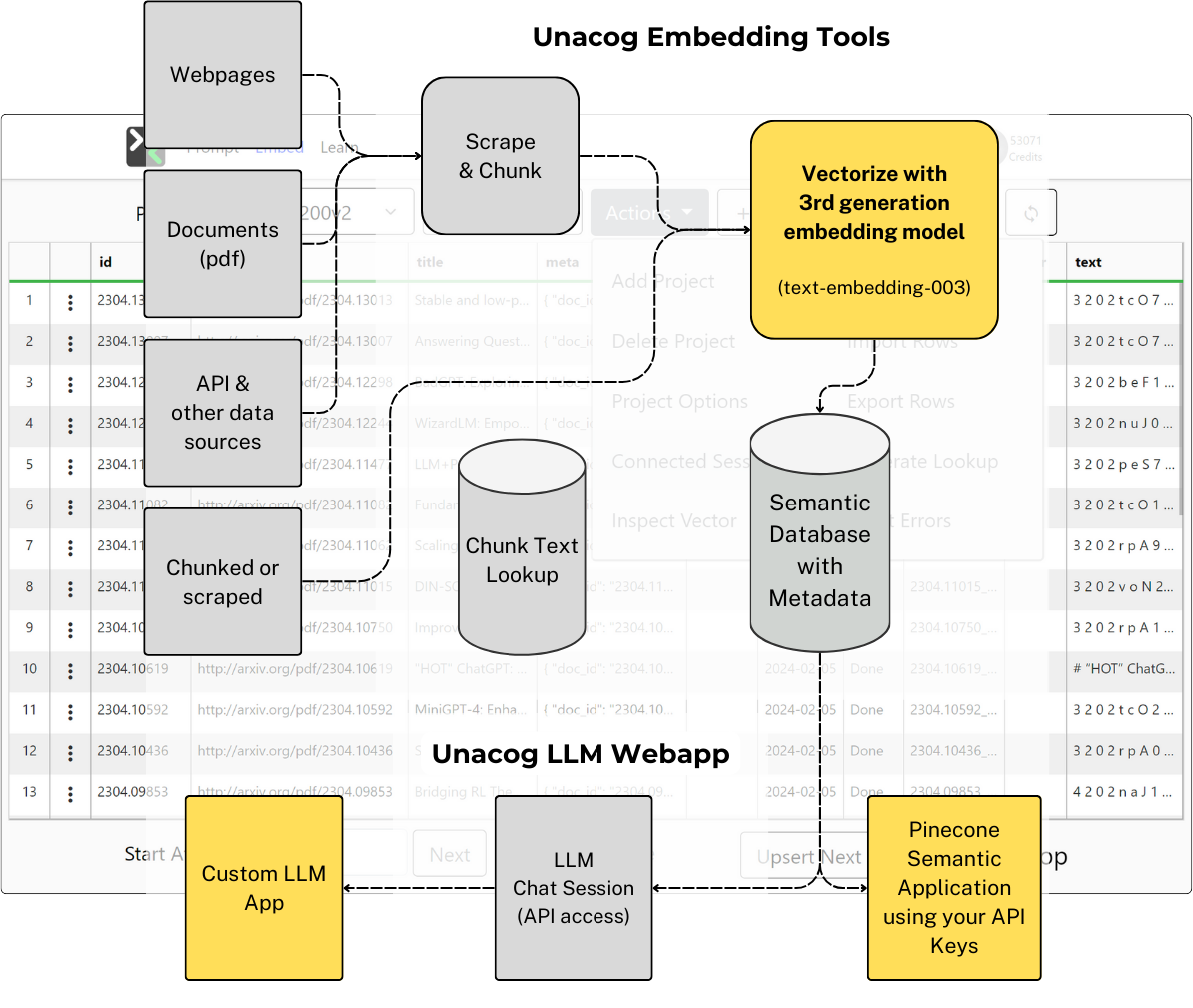
The first thing you learn building a RAG pipeline is that chunking matters more than you think. You take a document, split it into pieces, embed each piece into a vector, store it. When a user asks a question, you embed the question, find the most similar vectors, and feed those chunks to the LLM as context.
We built four chunking strategies — size-based, sentence-based with bidirectional overlap, recursive character splitting, and no chunking at all — and tested them against real data at scale. The takeaway wasn't that one strategy wins. Different documents need different approaches. A research paper with clear section breaks behaves differently than a transcript. A FAQ behaves differently than a narrative. I wrote up the technical details and results at the time.
Scale
To prove the system worked, we indexed real data.
arXiv AI papers
2,800+ arXiv AI papers across four Pinecone indexes at different chunk sizes — same corpus, four ways to slice it, so we could directly compare retrieval quality. Over a million vectors.
COVID research
389 COVID research documents with two splitting strategies. We recorded a walkthrough of the full pipeline — scraping, cleaning, chunking, upserting, and querying the corpus end-to-end.

The Bible
The full Bible indexed as individual verses and as full chapters — our stress test for granularity. Same text, two radically different chunk sizes, so we could see what each resolution surfaced.

Billboard Top 100
And Billboard Top 100 songs at four granularities: full song, stanza, verse, and double-stanza. This one led somewhere unexpected — more on that below.
The embedding tool
We also built a visual embedding tool so non-developers could ingest and test their own data against the pipeline — project configuration, chunking options, error handling, and connected test sessions, all through a GUI.
Small-to-Big Retrieval
One pattern we developed was what people now call "small-to-big" retrieval — match on a small chunk for precision, then expand to surrounding context for completeness.
The implementation: chunk IDs are padded with their position ({docId}_00001_00005 — chunk 1 of 5). When you get a match, you look up adjacent chunks from the same document and merge them. The trick is handling overlap at boundaries — when chunks share content, you need to deduplicate rather than concatenate. We exposed three knobs: topK (how many chunks to retrieve), includeK (how many to use in the prompt), and contextK (how many adjacent chunks to expand each match with).
This pattern shows up in most RAG frameworks now. We were building it by hand because the frameworks didn't exist yet.
The Discovery: Subjective Metrics
The song lyrics demo is where something unexpected happened.
We were doing standard semantic retrieval — embed a query, find similar songs. It worked, but the results were limited. "Find songs similar to this one" only gets you so far when similarity is a single axis: cosine distance.
So we built a metrics system. Ten categories — romantic, comedic, violent, political, religious, sad, motivational, mature, seasonal, inappropriate language. For each song, we ran prompts that asked the LLM to rate the content 0-10 on each dimension. We stored these scores as numeric metadata on the embeddings.
Now retrieval had multiple axes. Instead of just "find similar songs," you could say "find songs similar to X where romantic is above 7 and violent is below 3." That query is impossible with pure embedding similarity. You need the metadata dimensions.
This changed how I think about retrieval. Cosine similarity gives you one axis: how semantically close are these pieces of text? Subjective metrics give you as many axes as you can define. Emotional intensity. Bias level. Technical complexity. Persuasion tactics. Whatever matters for your domain. The practical impact: retrieval that actually matches what the user wants, not just what's textually similar.
This Became Klyde
The metrics system was too useful to leave inside a demo. We extracted it into a Chrome extension called Klyde — a tool that lets you perform subjective analysis on any content in the browser.
You define prompt sets (collections of scoring prompts for a domain), point them at a web page or text selection, and get numeric scores back. International news analysis with 7 dimensions. Persuasion detection with 8 rhetorical markers. Email tone analysis. Whatever you need.
The scores feed back into vector retrieval as metadata filters. The Chrome extension solved the data collection problem — how do you get content scored and indexed without a custom pipeline for every use case? You browse the web and analyze as you go.
What I Think About RAG Now
RAG isn't dead. Vector embeddings let LLMs understand similarity without reading the full text. For large datasets where you can't stuff everything into the context window, it's still the only practical approach.
But people tried to use RAG for everything — memory, conversation history, user preferences. What we're seeing now with modern agent architectures is that for a lot of those use cases, the better approach is to let the agent navigate the file system and read documents when it needs them. That's more natural for how these models work. And the thing that actually makes LLMs better isn't better retrieval — it's better models. Every time the underlying model improves, everything built on top changes.
Subjective metrics are a different story. Most RAG systems are still doing single-axis cosine similarity with maybe some keyword filtering. Multi-dimensional scoring — storing LLM-generated ratings as metadata and filtering on them at query time — is still underexplored. It works, and almost nobody's doing it.
What Happened to Unacog
Sam and I eventually went separate ways. The platform isn't actively maintained. The demos still work.
The chunking strategies, the small-to-big pattern, the subjective metrics discovery — all of that carried directly into Klyde, into how I built Eureka's entity system, into how I think about context in every project since. The platform died but the ideas didn't.